Inter-American Development Bank
The Inter-American Development Bank (IDB) partnered with Link Digital to revamp its existing open data catalogue, considerably extending its functionality to bring it into line to meet the expectations of modern data users and the challenges of the rapidly evolving open data ecosystem. A complex project successfully completed within a very tight deadline, the new open data catalogue provides advanced, multilingual search and sharing capabilities for the organisation’s open datasets.
The project involved the following technology services:
Link Digital began work on the site in October 2024 and the new catalogue went live in April 2025. The tight project turnaround was necessary because the IDB contract with the proprietary software provider managing the catalogue was ending. Link Digital is now working with the IDB on phase II of the project and providing ongoing managed hosting for the new catalogue.
Link to the site
Founded in 1959, the IDB is an international development finance institution headquartered in Washington, D.C. It is the largest provider of development financing for Latin America and the Caribbean. With 48 member countries—including 26 borrowing members from the region and 22 non-borrowing members from Asia, Europe, and North America—the IDB is dedicated to improving lives by providing financial and technical support to national and sub-national governments and institutions. The Bank also delivers policy advice, cutting-edge research, and training. Together with IDB Invest, which supports the private sector, and IDB Lab, the innovation laboratory that tests and scales entrepreneurial solutions for inclusion and sustainability, the IDB Group mobilises capital, knowledge, and partnerships to address the region’s most pressing challenges and promote inclusive, sustainable development.
The primary objective of the new open data catalogue was to maximise the IDB’s value as a knowledge bank by generating and disseminating research and insights that help foster development in addition to increasing access to key IDB datasets and improving the sustainability, searchability and interoperability of IDB data. The project updates a previous open data catalogue, built in 2015. A major refresh and reimagining were desired to bring the catalogue in-line with modern standards and user expectations in order to meet the challenges arising from both a rapidly evolving open data ecosystem and increasing data needs from governments and institutions.
Another major driver of the project was the strong desire to migrate the data catalogue from a proprietary to an open-source platform. The previous catalogue was built on a proprietary, closed-source system that limited scalability and customisation capabilities, unlike the new open-source solution. The conclusion of the contract with this provider offered the opportunity to make major changes.
The IDB’s open data team undertook an extensive process to scope out what was required in the new catalogue. This included interviewing external and internal stakeholders, a comparison of data catalogue technology solutions used by other organisations, including their look and what features they offered, and an analysis of the various open source software technologies on offer.
CKAN emerged as the option that most aligned with the IDB’s vision. The IDB’s open data team were particularly attracted by CKAN’s wide range of extensions and easy customisation, which gave them the ability to do some of the work on the catalogue themselves. It also gave the IDB flexibility to make further changes and scale the catalogue up to meet the emerging demands of data users and/or shifts in the Bank’s situation. The IDB’s open data team was also energised by the prospect of contributing to the CKAN software’s growing international community and has even included CKAN in its open source software catalogue.
The result is an attractive, high-impact open data catalogue designed to enhance the discoverability and easy reusability of IDB datasets. It achieves this by leveraging a scalable architecture and adhering to best-practice metadata standards to ensure international interoperability with data harvesters.
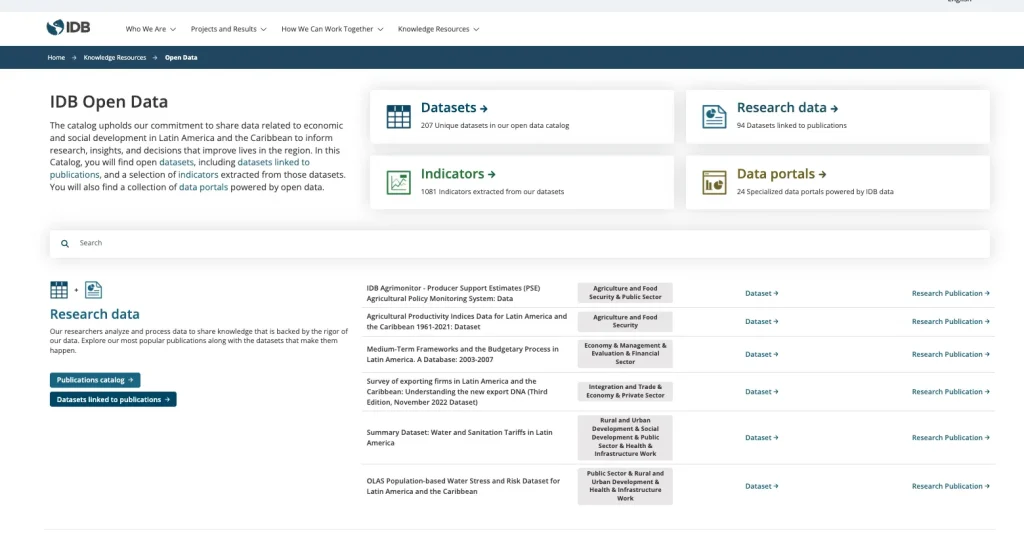
The catalogue currently hosts over 200 datasets. Much of this data focuses on economic and social development, including detailed information on macroeconomic and social indicators for the Latin American and Caribbean region. Most of the data is tabular, provided in formats such as CSV, Excel spreadsheets (.xls, .xlsx), Stata files (.dta), and R data files (.rds, .RData). There are also numerous PDF documents. The data includes several extremely large datasets, which presented significant challenges for the CKAN software (discussed later).
In terms of overall presentation, the new catalogue has been configured into four categories.
| Objective | Solution | Outcome |
| Scalability | CKAN core optimisation | 26x Faster API Response |
| Interoperability | DCAT Metadata Mapping | Global Data Harvesting |
| Usability | PoolParty Integration | Reduced Data Discovery Time |
| Inclusivity | Multilingual Logic Core | Expanded Reach in LATAM/Caribbean |
CKAN operates as the open data catalogue’s spine, providing advanced metadata support and effective cataloguing and searching. Link Digital worked closely with the IDB open data team on several features, which all contribute to bringing the catalogue in line with global best practice.
The catalogue is fully Data Catalog Vocabulary (DCAT) compliant.
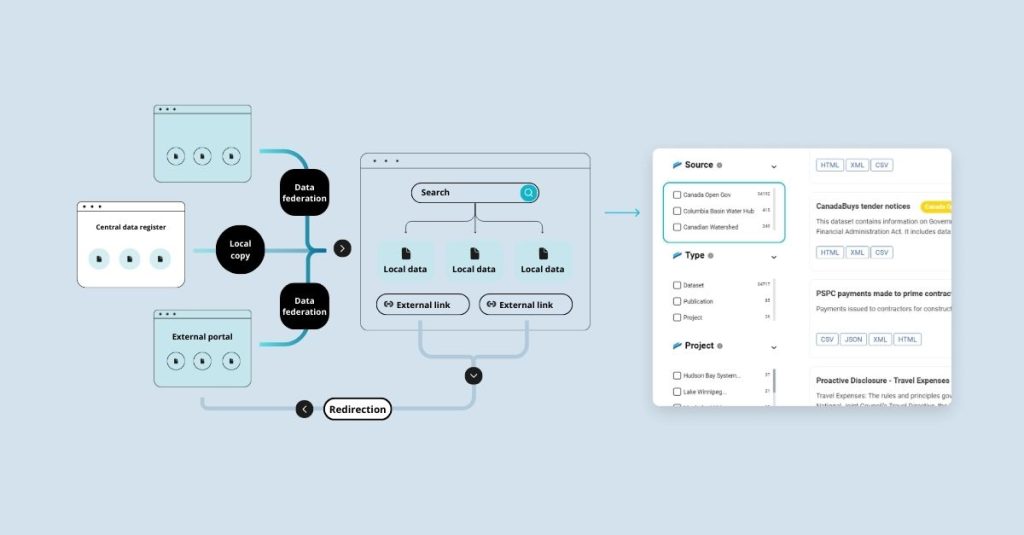
DCAT is an RDF vocabulary designed for describing datasets to enhance interoperability between systems that manage and expose data, such as data portals and data catalogues. It provides a standardised metadata model and vocabulary for data publishers to describe datasets and data services, enabling these systems to better exchange and integrate metadata, thereby making data more readable by a wider range of applications and, thus, more discoverable and reusable. While uptake is by no means universal, DCAT is arguably the closest thing that currently exists to a worldwide metadata standard for describing datasets in data portals and catalogues, and it is widely used by many open data portals and catalogues globally, including extensively in Latin America.
The IDB’s open data team gave Link Digital an application profile based on the DCAT standard to describe their data. Link Digital then designed a data schema to accommodate this and mapped it onto CKAN’s existing internal schema, using ckanext-DCAT. This extension allows CKAN to export and publish metadata in DCAT format and enables CKAN-based data catalogues to be integrated with other data catalogues or platforms that use DCAT metadata.
A controlled vocabulary is a carefully selected and standardised list of terms used to consistently tag, describe, and index datasets via metadata for improved discoverability and retrieval. The IDB’s open data team uses PoolParty, a non-open-source semantic suite, to manage the controlled vocabularies they use to categorise datasets within the catalogue, which Link Digital integrated into the CKAN application.
The IDB open data team were keen to introduce a predetermined list of metadata terms that those uploading data to the catalogue can use. This reduces possible confusion caused by unstructured language and variant and incorrect spellings of things like social and statistical terms, countries, etc, by ensuring that only the preferred term can be used and that it corresponds to a single subject. Having standardised themes also enables users to search for and retrieve the dataset(s) they need more easily.
A Digital Object Identifier (DOI) is a unique combination of letters and numbers used to provide a permanent link to the location of an object, such as a document, image, dataset, or research paper, on the Internet, even if its URL changes.
Using an extension called ckanext-doi, Link Digital was able to seamlessly migrate legacy DOIs to the new CKAN powered catalogue and connect it to the registration agency DataCite to make the process of minting new DOIs automatic. The fact that users will always have access to the catalogue’s resources encourages openness and keeps the site aligned with the IDB’s policy of promoting persistent access to knowledge resources. The use of DataCite also makes datasets on IDB’s catalogue findable in other repositories, for example DataCite Commons, increasing their discoverability.
The default language of the old open data catalogue was English, with some Spanish language functionality. The IDB were keen to expand this to cover all four official Bank languages: English, Spanish, French and Portuguese. While basic language support is a standard out of the box feature of CKAN, the software’s default ability in this area was limited. It did not support complete translations and did not allow users to toggle between multiple languages in the one CKAN instance.
The IDB’s open data team undertook the time consuming task of translating everything on the catalogue – not just site headings and language and metadata but all the datasets as well – and Link Digital extended CKAN’s core functionality to make all the content on the site accessible in four languages and enable users to toggle between them. This removes a major barrier to data discoverability and reuse by significantly expanding the accessibility of the site to non-English speakers in Latin America and the Caribbean.
This is the first catalogue to use Link Digital’s new auditing functionality. Basically, every event in the catalogue is now being sent to the Amazon CloudWatch, providing Link Digital with a log of everything that occurs, which will improve maintenance and make it easier to maintain security.
Meeting the four-month deadline for the catalogue’s completion – necessitated by the approaching end of contract with an existing software provider – was made possible by the considerable preparation undertaken by the IDB data team before Link Digital commenced work. The IDB open data team created approximately one thousand new indicators for the catalogue and did a great deal of work cleaning and restructuring the data, including aligning it for compliance with the DCAT standard.
Nonetheless, the catalogue was a complex project that required considerable hands-on work and out of the box thinking on Link Digital’s part. These challenges primarily related to the size of some of the IDB’s datasets, which are far larger than those typically hosted on CKAN catalogues and open data portals.
For example, the IDB’s Social Indicators of Latin America and the Caribbean dataset alone comprises approximately 12 million rows of data. It was very much a hands-on process to optimise code and customise indexes so that the performance of the catalogue when working with very large datasets was more than twenty times faster than the default.
Accessing these large datasets using the existing CKAN architecture was challenging, as the ckanext-xloader extension normally used to load them was failing. Beyond that, just having some of these datasets in the catalogue was going to present challenges for querying. The number of rows and the size of the data meant that the types of queries users were going to run could take tens of seconds to run or they would not work at all because the API would just time out. Fixing these problems required Link Digital to improve the catalogue’s API and the performance of CKAN for previewing large datasets more generally.
Link Digital was required to do other hands-on work with the IDB’s data to get the data loaded into the CKAN site. Link Digital used the new Table Designer feature for these very large datasets. This allowed the IDB to push partial updates for some of the large datasets rather than reloading the entire file, by giving them an API that allowed them to only update records that needed to be changed and added. And by maintaining that table in the database the way that Table Designer does, it allowed Link Digital to add custom indexes for the particularly large datasets.
Indexes are a feature of Postgres that lets developers create a fast way to look up a record based on some of the filters that they have provided. Link Digital looked at the queries the IDB needed and chose combinations of columns to index for each of these datasets that has these queries run far faster. Loading the data was something that Link Digital had to help with initially because there was so much to load, but now the IDB open data team have procedures on their side to do it using the API. But creating the indexes was very much a hands-on process that Link Digital had to do directly to the Postgres DataStore database, tweaking it so that the performance would be much better than had the IDB used the default procedure.
Pages on the IDB’s Open Data catalogue now load almost immediately and API calls that are part of the page when you are getting information about the dataset, which were extremely slow, have been fixed as well so they are faster. This work necessitated several changes to CKAN’s core code to optimise how the software handles very large files. These optimisations will be included in the next CKAN update, release 2.12, so that all the software’s users can benefit from them.
A smaller challenge related to the IDB’s open data team wanting the functionality to prepare a whole zip file of a dataset for users to download. This could have led to potential misuse of the catalogue if several users with malicious intent opened the hit button to create a zip file at the same time, resulting in a spike in load that could have serious problems for the back end of the catalogue. To get around this, Link Digital pre-built zip files in advance and uploaded these to the Amazon cloud service for the IDB open data team to manage the download. If there is no change to the dataset once it is compiled and uploaded to the catalogue, the pre-built zip file remains on the site and can be easily downloaded.
Data migration from the old open data catalogue was also tricky and took a considerable amount of time because of the number of datasets.
Despite being relatively new, the catalogue is already showing positive impact, with several Latin American governments expressing interest in the platform and exploring ways to make use of it. The IDB’s open data team has also found the workflow process involved in publishing new datasets to the catalogue is easier and has far less friction.
The introduction of controlled vocabulary is proving particularly helpful. The publishing process will continue to improve as the IDB data team finalises work on their new internal publishing workflow.
The CKAN community also benefits and here are some of the core CKAN contributions that came directly from work on IDB open data:
Link Digital is already working with IDB on phase 2 of the project to continue expanding the benefits of the solution. This includes:
The implementation of additional accessibility features to bring the catalogue fully into line with Web Content Accessibility Guidelines (WCAG) 2.1.