We have grown used to reading and hearing about the enormous potential of artificial intelligence (AI). The rapidly evolving nature of the technology makes it difficult to pinpoint specific shifts in the relationship between AI and open data.
One emerging discussion that Link Digital is keen to highlight concerns the proposition that the intersection between the two involves far more than open data’s role as raw material to train and operate large machine learning models, the focus of so much of the commentary to date.
In addition to surveying some of the public policy benefits that can result from AI and open data working together, the following post will look beyond how open data benefits AI and examine what AI can potentially contribute to open data.
The relationship between open data and AI
The Open Knowledge Foundation defines open data as data that ‘anyone can freely access, use, modify, and share [the data] for any purpose (subject, at most, to requirements that preserve provenance and openness).’ Open data is generally thought to benefit AI by providing usable training data. As a July 2024 report by the European Union (EU) put it:
The transformative potential of AI originates from its ability to analyse data at scale, and to notice and internalise patterns and correlations in that data that humans (or fully deterministic algorithms) would struggle to identify. In simpler terms: modern AIs flourish especially if they can be trained on large volumes of data and when they are used in relation to large volumes of data.
There is considerable evidence that AI, combined with open data, is reshaping how the public sector works, helping to drive improved policy insights and formulation. AI can quickly synthesize large amounts of open data to detect patterns and trends that might otherwise not have been discoverable, enabling policy makers to come to more focused and timely decisions and combine data across disciplines to derive new insights.
This, in turn, offers the promise of a more holistic approach to decision making that can span or break down silos. Writing on the Spanish Government’s open data portal, Datos.gob.es, the World Wide Web Foundation’s senior researcher Carlos Iglesias argues that the synergy of open data and AI can go a step further and help facilitate more collaborative data analysis.
Through this process, multiple stakeholders can work together on complex problems and find answers through open data. This would also lead to increased collaboration among researchers, policymakers, and civil society communities in harnessing the full potential of open data to address social challenges. Additionally, this type of collaborative analysis would contribute to improving transparency and inclusivity in decision-making processes.
In agriculture, for example, Rutgers University Policy Lab states that the use of AI and open data to collect and analyse large amounts of data is helping farmers and related policy makers to analyse soil sample conditions and weather patterns. ‘AI tools and applications also help in managing logistics and making optimal business decisions, including identification of crop sequences for profit maximization contextualized to external variables.’
The EU report cited previously notes that combining data on weather, seed genetics, soil characteristics, and environmental conditions has the potential to train AI to deliver important insights on the factors affecting agricultural production across Europe. ‘Such a system could be used to aid decision-making to increase crop yields, prevent plant disease, or optimize other business decisions.’
Other examples discussed in this article on the EU’s open data portal, data.europa.eu, include combining open data on climate and energy with AI to develop an app to provide citizens with recommendations for more sustainable decisions on energy in Croatia, and the way in which the European Union’s European Cancer Imaging Initiative has used large open datasets and AI to battle cancer.
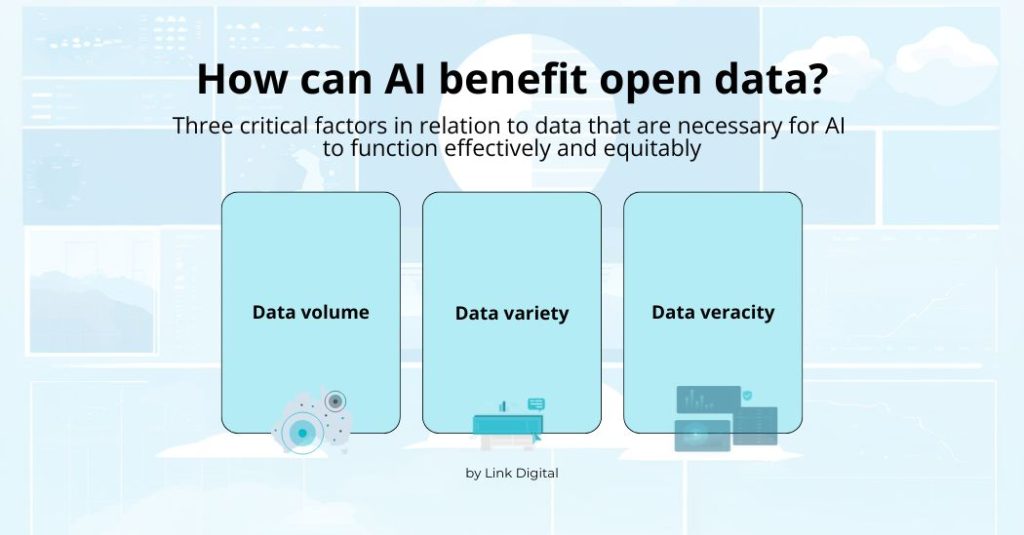
How can AI benefit open data?
The EU report lists three critical factors in relation to data that are necessary for AI to function effectively and equitably: data volume; data variety, i.e., diverse data sources to enhance AI’s ability to perform better in real world scenarios and avoid bias; and data veracity, in other words, data that is high quality and accurate. The EU report notes that the volume and variety factors have to some extent been satisfied by the breadth of open data available to AI to date. It contends, however, that data quality, ‘a priority to unlock the synergy between open data and AI,’ requires a more deliberately focused effort. A similar sentiment, that high-quality data is essential for a more equitable and efficient AI, was expressed in this post.
The intersection of AI and data quality is so crucial that the public sector data think tank Gov Lab argued in a report last year that it potentially holds the key to what it terms the ‘Fourth Wave of Open Data.’ The Third Wave of Open Data involved the proposition that the open data ecosystem had moved beyond focusing on simplifying data and its impacts, to how governments, private corporations and civil society organisations can better know and understand the data they have and share it to provide improved products and services, and a more informed citizenry. Gov Lab describes the Fourth Wave as ‘the next frontier of open data where open data is more conversational and AI ready, data quality and provenance are centre stage, a whole range of new use cases from open data are feasible and there are new avenues of data collaboration.’
As part of this, Gov Lab asserts it is in the interests of AI developers to focus more on the quality requirements of open data, a process that could also potentially address many of the pain points in open data access and usage. According to Gov Lab this could include:
- Enhancing transparency and documentation, which could help users better evaluate data lineage, quality and impact.
- Increasing the focus on data quality and integrity, including AI playing a role in data cleaning and preparation, and identifying and correcting errors and filling gaps.
There is also a role for AI in promoting interoperability and consistent data and metadata standards to enable more efficient and effective data re-use. Iglesias notes that this work could also involve ‘the development of common data standards, metadata frameworks, and APIs to facilitate the integration of open data with AI technologies, further expanding the possibilities of automating the combination of data from diverse sources.’
Some even argue that open data’s centrality to AI is a powerful argument not only for governments to focus on creating better open data infrastructure and policies to prioritise data quality, discoverability and useability, but to make more government data, particularly high value datasets, more open. As Open Data Institute framed it in a June 2020 blog post, this could be essential to heading off what some term a looming ‘data winter.’ The result of both the drying up of open datasets to train AI and the trend of data producers locking up open access data sets, this is shifting AI from its traditional reliance on manually crafted datasets to collecting vast amounts of data from the web, with all the legal, ethical and privacy concerns involved.
The Gov Lab report contends a focus by AI developers on data quality could also help counter some of the ethical and policy challenges arising from data use by large language AI models, including improving protections around how AI obtains access to training materials and greater protection around the use of personal data.
Improving transparency and documentation of open data can not only foster ethical and responsible use throughout the data lifecycle, but can also help data holders and users to better evaluate the lineage, quality and impact of the output. This is particularly important when using open data for inference and insight generation, data and model augmentation, and open ended exploration.
Another benefit of increased focus on quality open data noted by Iglesias is improved transparency regarding AI’s algorithmic functioning. This could contribute to building public trust and transparency not only in large language learning models, but in the government policies and decisions made based on information derived from them.
Conclusion
The intersection of AI and open data is transforming government decision-making by enabling policymakers to synthesise large amounts of diverse data across disciplines, breaking down silos and generating new insights. But whether it is also shifting the relationship between the two in a way that could deliver substantial benefits to the open data community is a discussion Link Digital will continue to follow with great interest.
Want to talk more about how you can unlock the power of your open data?
Contact us and one of our data experts will be in touch.



