This blog post was co-authored by Ian Ward, Senior Solutions Architect at Link Digital, with input by Full Stack Developer/Architect, Sergey Motornyuk.
Diagrams are done by Anastasiia Shevtsova, Link Digital UI/UX designer.
Table of contents
A data publishing workflow is a structured process for preparing, reviewing and publishing datasets to ensure data quality, maximise accessibility and discoverability, and ensure compliance with any legal and other standards. In a presentation to the recent 2024 Canadian Open Data Summit, Ian Ward, Link Digital’s Senior Solutions Architect, outlined some of the great publishing workflows created using the powerful open source software known as CKAN – the Comprehensive Knowledge Archive Network.
Let’s recap this presentation, which set out eight of the tasks required in a data workflow pattern. These were illustrated with examples of CKAN-powered data catalogues and data portals, some of which Link Digital worked on, and the wide variety of extensions which can add additional features and integrations to the CKAN’s core software.
Metadata ingestion
Data catalogues and open data portals are built on metadata. The better the metadata, the easier it is for users to find exactly the data they need by searching, filtering or linking from other data sources. In data-oriented organisations publishers will already be tracking metadata about the data they need to share. To publish or update a dataset these organisations just need to convert their metadata into the right metadata schema for ingestion into the catalogue or portal, and push it with an application programming interface or API – protocols and software that enable a connection between computers or between computer programs.
The Canadian Government’s national open data portal, open.canada.ca was built using an extensive metadata schema, including controlled vocabularies, fully bilingual fields and geographic information. Using the ckanext-scheming extension, this metadata schema becomes a natural part of the CKAN API. New fields work just like built-in fields and appear automatically in forms for users entering metadata, and new and changed validation rules are integrated seamlessly.
The ckanext-scheming extension uses a JSON data exchange format or YAML-based metadata schema to define all dataset and resource metadata fields, and vocabularies and validation rules, without needing to change or extend the CKAN software itself. Using JSON or YAML data to represent a metadata schema is powerful. Metadata schemas themselves are exposed by an API so they can be shared and built on or integrated into other tools that work with the catalogue metadata.
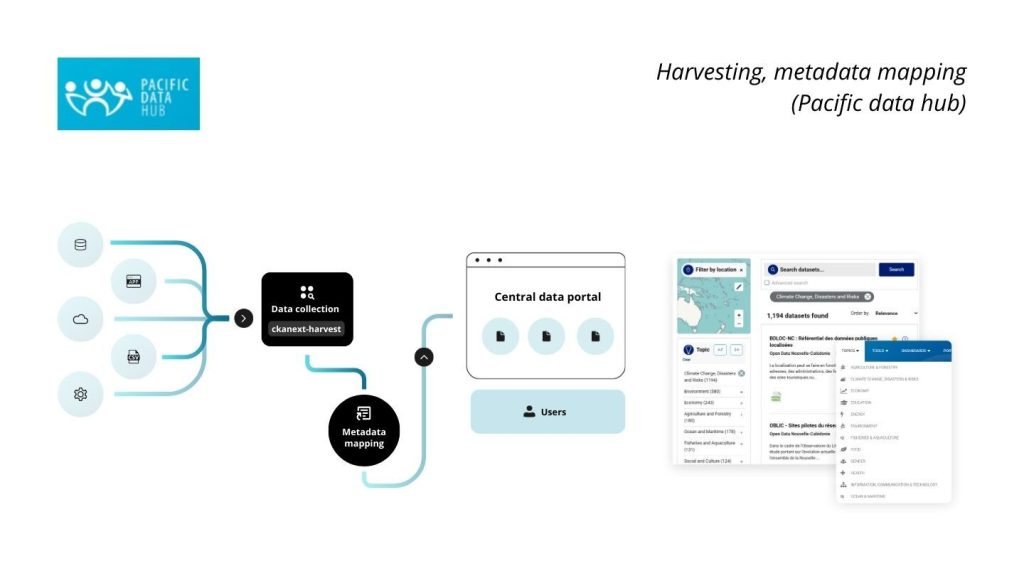
Another approach is used by Pacific Data Hub, an open data portal that serves as a gateway to the most comprehensive data collection of relevance to the 22 Pacific Island nations, which Link Digital helped build. Metadata from many sources, including existing local data portals, old archives and other data sources, is centralised in the data catalogue. This portal periodically collects and combines information using the ckanext-harvest extension from many third-party sites, most of which are not CKAN portals. Separate workflows are created with chanext-harvest for each individual data source. After receiving the data, rules are used for mapping external data to the expected schema, so data collected from various unrelated sites with completely different structures are displayed as a combined series of datasets.
Data validation
Data validation involves checking data to ensure it meets quality criteria, such as completeness, accuracy, and reliability. So much published data is raw and unvalidated that it’s estimated between 50 and 80% of the time spent by people using the data is just cleaning it first. Data validation saves users time and makes sure all the data published in a catalogue is usable.
For example, data published on open.canada.ca can either be a link to an external resource or a file uploaded into the catalogue. For uploaded files, the ckanext-validation extension can be used to generate a report (in both Canada’s official languages, English and French) on the data’s validity. This covers off the basics, like ‘are there unique column headings’ and ‘are there any blank or duplicated rows.’ Only when data checks out as valid will it be loaded using xloader into the CKAN datastore. This data can then be previewed in a searchable table and enabled as a data API. This also acts to encourage users to upload valid data, because while invalid data isn’t prevented from being published, invalid data won’t have the visualisation and API features behind it.
Federation
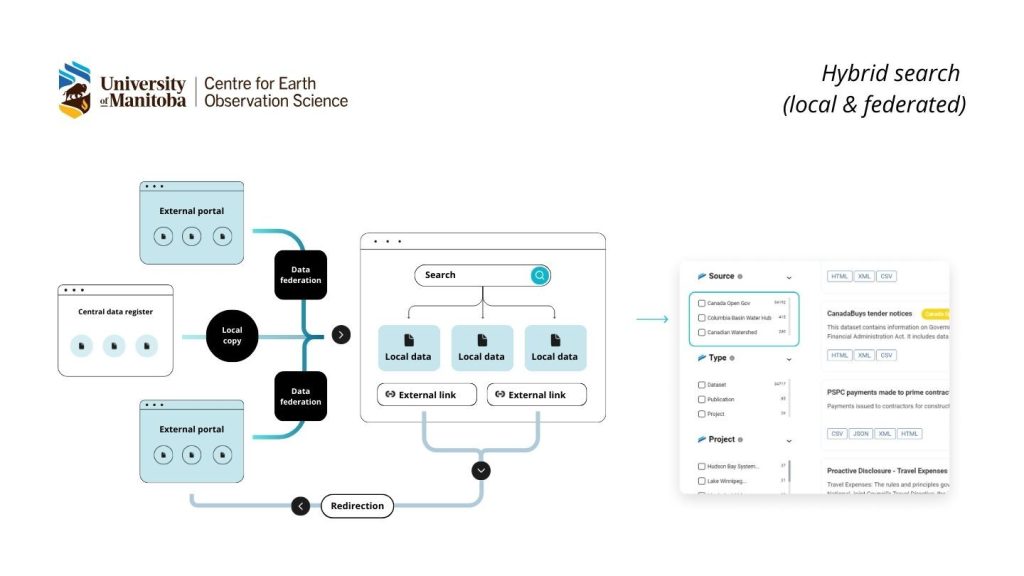
Federation, or republishing metadata already published in other catalogues, can create a one-stop-shop for data users. A good example is another CKAN powered portal developed by Link Digital, and managed by University of Manitoba’s Centre for Earth Observation Science, the Canadian Watershed Information Network. An internal data management platform that collects and manages a large array of climate data, including spatial data, and analyses and shares it with researchers, it combines both local and federated data into a single search interface. Federation is run periodically to ensure high-quality results.
Multi-tenant publishing
A different way to host information from multiple sources, when some of those sources don’t already run their own catalogue, is to give them accounts on a shared CKAN catalogue. For example, Quebec’s provincial open data catalogue has accounts and organisations for its municipalities so they can host and publish data without needing to maintain their own separate catalogue. Since there’s no single vendor for requiring a separate contract for each city, if you run CKAN there’s no restrictions on how you share or run a catalogue.
Data aggregation
It can also be useful to aggregate the same data from multiple sources into a single dataset. The NSW Flood Data Portal, which link Digital worked on, involves researchers working in parallel and collecting data for several datasets with a total volume of tens of gigabytes. These datasets consist of many files, and it is time consuming to transfer them individually. In addition, a researcher will register datasets gradually, publishing information that depends on other datasets which haven’t been created yet. This increases the risk of uploading a file to the wrong place, among other errors.
A separate program called the Data Upload Tool was created for researchers to run on their computers. Researchers specify the directory with the information and the program shows them approximately which datasets will be created from it. Researchers edit the metadata directly in the program, such as the name, description or license of the dataset. The Data Upload Tool shows them a list of all datasets and all resources that will be included in these datasets.
After checking the data, the researcher clicks on a button to validate it using the CKAN API. When all the errors are fixed and the CKAN API says that the dataset can be created, the Data Upload Tool can create all the resources, datasets and upload all the files. The program monitors what has already been created and how much has already been uploaded, so even in the event of a power outage, the researcher will be able to continue uploading exactly from the moment where he or she stopped. Finally, when everything is created, again using the CKAN API, the application tells the portal that it is finished, and all the created data is published together.
Format conversion
Depending on your goal and the tools you have chosen, a data file published in a catalogue might not be the ideal format. The British Columbia Data Catalogue generates different data formats for published geospatial data as part of the publishing process. The City of Toronto Open Data Portal generates alternate formats for both geospatial and tabular data as part of a pipeline which we’ll touch on in a little more detail under data quality and review.
Filtering and packaging
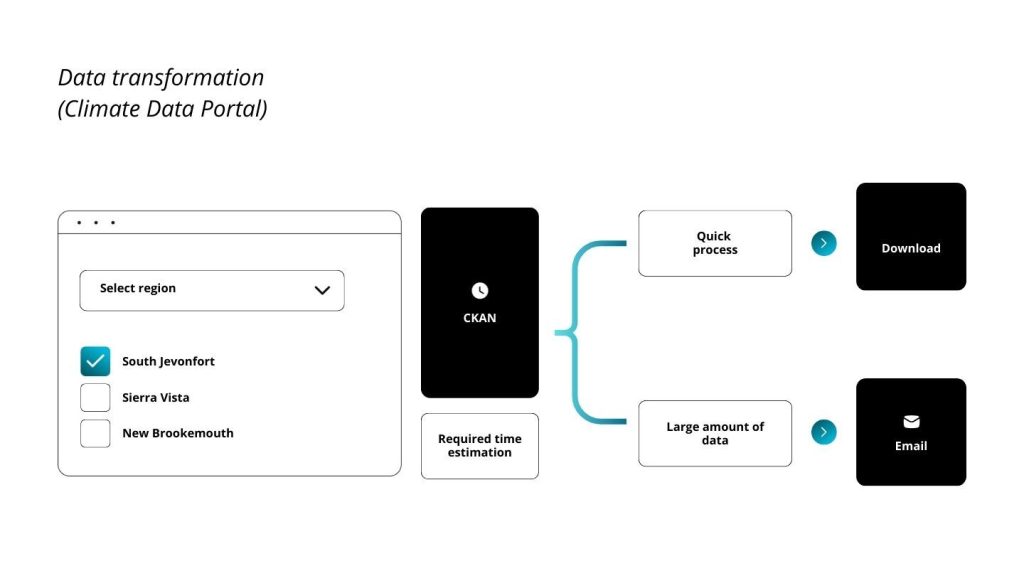
Sometimes data custodians are presented with too much data. Data filtering patterns are used to identify subsets of data based on specific criteria, reducing the volume of data to only what’s necessary for analysis or processing. Data packaging patterns involve structuring, grouping, and storing data in a way that makes it more accessible and manageable. For registered users on the soon to be launched New South Wales Climate Data Portal it is possible to download filtered geospatial data on certain regions or other parameters. When a filtered download is requested, CKAN estimates the time required to generate the data. For quick requests the file is generated and downloaded immediately but when a large amount of data is requested it will be generated in the background and the user will be emailed a link once the process has completed.
Data quality and review
It is vital to always deliver the best quality data to users. Data validation helps but sometimes you need an expert to review data before it’s published. On open.canada.ca new datasets are uploaded to one internal ‘Registry’ CKAN instance and put in a queue to be reviewed. Individual members of the business team check the metadata and data for accessibility and compliance with official language requirements. Once any required changes are made and the dataset is approved it moves to the public ‘Portal’ CKAN instance. The team behind the City of Toronto Open Data Portal go a step further. Departments can’t simply log in and publish data, instead the open data team works with data owners and builds an individual ETL – extract, transform, load – pipeline to process every dataset. These pipelines cache different versions of the data by uploading them to CKAN and push data into the CKAN datastore with awareness of the types and descriptions for every column. This process guarantees that data is always up to date, valid and available through CKAN’s APIs and visualizations, although there are limitations based on ETL resources and the open data team’s time to integrate new datasets.
Conclusion
This article has covered some of the workflow patterns enabled by CKAN. Many of the tools referred to above are open source, reusable extensions. Almost anything you might need for a data catalogue or open data portal is possible with CKAN and can help make data more discoverable and higher quality for publishing, internally or externally.
Want to improve your data workflow patterns?
Contact us and one of our data experts will be in touch.



