The modern data challenge
Open data portals have matured significantly over the past decade. Many organisations now operate CKAN – Comprehensive Knowledge Archive Network – instances containing hundreds, if not thousands of datasets. Metadata is structured, application programming interfaces are exposed, and search is functional.
Yet a persistent friction remains: discovery and interpretation.
Users still struggle to locate the right dataset when they don’t know the exact terminology. They manually inspect metadata. They download files to understand the structure. In practice, access exists, but usability often lags far behind.
Ask AI, a new Link Digital feature, introduces an AI-powered layer on top of CKAN to address that gap. The goal is straightforward. To make data portals conversational, contextual, and semantically searchable.
Moving beyond keyword search
Traditional CKAN search matches keywords in titles, descriptions, and other metadata fields. This works well when users know the exact phrasing used by publishers. But real-world users often search differently. A person looking for ‘police reports’ might miss a dataset labelled ‘crime statistics’. Someone interested in ‘ocean pollution’ may never type ‘marine ecosystem degradation’.
Ask AI introduces semantic similarity search. Instead of matching words, it matches meaning. Behind the scenes, dataset and resource metadata – along with supported document content – are converted into vector embeddings and stored in PostgreSQL using an extension called pgvector. When a user performs a search, the system retrieves results based on semantic proximity rather than simple text overlap.
The effect is immediate:
- Broader recall without sacrificing relevance
- Discovery across inconsistent terminology
- Reduced dependence on perfect metadata alignment
For organisations managing large portals, this materially improves dataset discoverability without requiring publishers to change workflows.
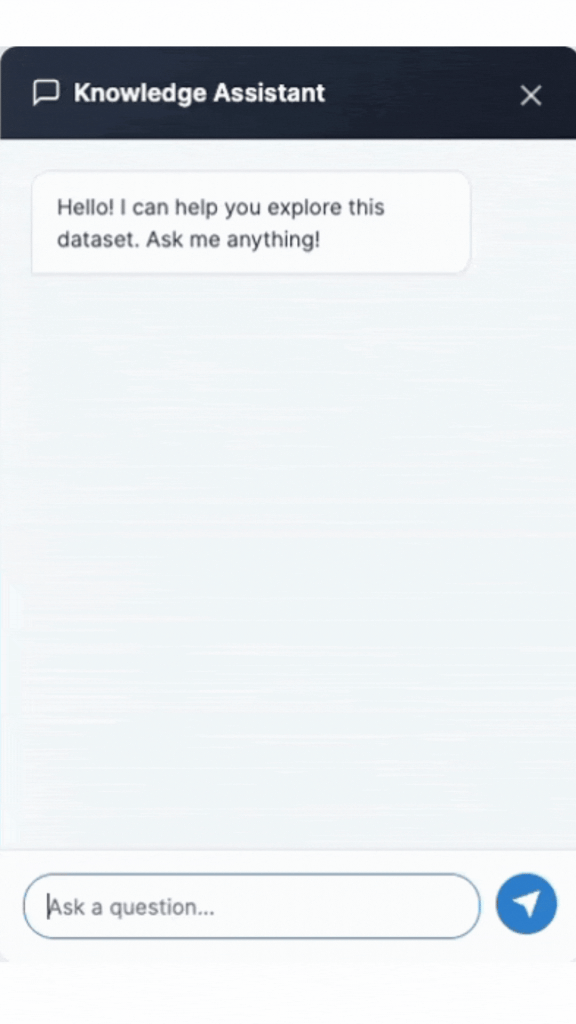
‘Ask AI’ at the dataset level
Each dataset page includes an ‘Ask AI’ interface. Instead of manually parsing descriptions, formats, or publisher information, users can ask direct questions:
- What is this dataset about?
- Who published it and when?
- What formats are available?
Dataset metadata is indexed and embedded in the background whenever a dataset is created or updated. This indexing process runs asynchronously to avoid impacting user performance. Updates are synchronised as needed to ensure AI responses remain aligned with current portal content.
The Ask AI assistant uses structured prompt templates to generate consistent, context-aware responses. It does not operate blindly but receives specific metadata context relevant to the dataset being viewed.
Document-level intelligence
Many portals host more than structured metadata. Reports, PDFs, spreadsheets, and presentations often contain critical context. Ask AI extends indexing beyond metadata to selected resource file types:
- DOCX
- TXT
- Markdown
- HTML
- CSV
- XLSX / XLS
- PPTX
Supported documents are processed and embedded into the vector store. Users can then query the content directly, including asking
- To summarise a report
- What are the key findings?
- Is there any mention of a specific topic?
Instead of downloading a 100-page PDF and searching it manually, users receive contextual responses grounded in the document itself. For organisations publishing analytical reports or policy documents, this significantly improves accessibility.
Querying tabular data without writing SQL
One of the most technically impactful features is the integration with CKAN’s DataStore extension. When users ask analytical questions about tabular data, Ask AI can generate SQL queries through the DataStore API. Retrieved records are then provided as structured context to the language model to produce a response.
For example, a simple analytical request may trigger a generated query such as:
SELECT fields
FROM resource_table
LIMIT N
Users do not see or write SQL. The system constructs queries dynamically based on schema awareness.
This lowers the barrier for non-technical users while preserving the integrity of the DataStore. It transforms the portal from a static repository into an interactive analytical surface. In addition, the assistant does not rely solely on live querying for every interaction. For DataStore-backed resources, we precompute lightweight statistical summaries, such as column types, value ranges, distinct counts, and basic aggregates. These summaries are stored and used as contextual hints during prompt construction.
This serves two purposes. First, it improves performance by reducing the need for exploratory SQL queries when the model only requires structural understanding. Second, it guides the model toward generating more accurate and efficient SQL, since it already has awareness of the dataset’s shape and characteristics.
Architecture overview
The architecture is intentionally conservative, and infrastructure aligned.
- Embeddings are stored in PostgreSQL using pgvector.
- Indexing runs in background jobs and synchronises on updates.
- No specialised caching layer is introduced; the system relies on model-level caching where applicable.
- Prompt templates ensure structured and repeatable interactions.
- Access is restricted to registered users for agent-based queries.
This design minimises operational complexity while remaining scalable within existing CKAN deployments. Organisations do not need to adopt an entirely new stack. The assistant integrates directly into the CKAN ecosystem.
Different organisations have different risk profiles and infrastructure constraints. Ask AI supports multiple backend options:
- Ollama (local models) for privacy-sensitive, on-premises deployments
- OpenAI for high-quality cloud-based responses
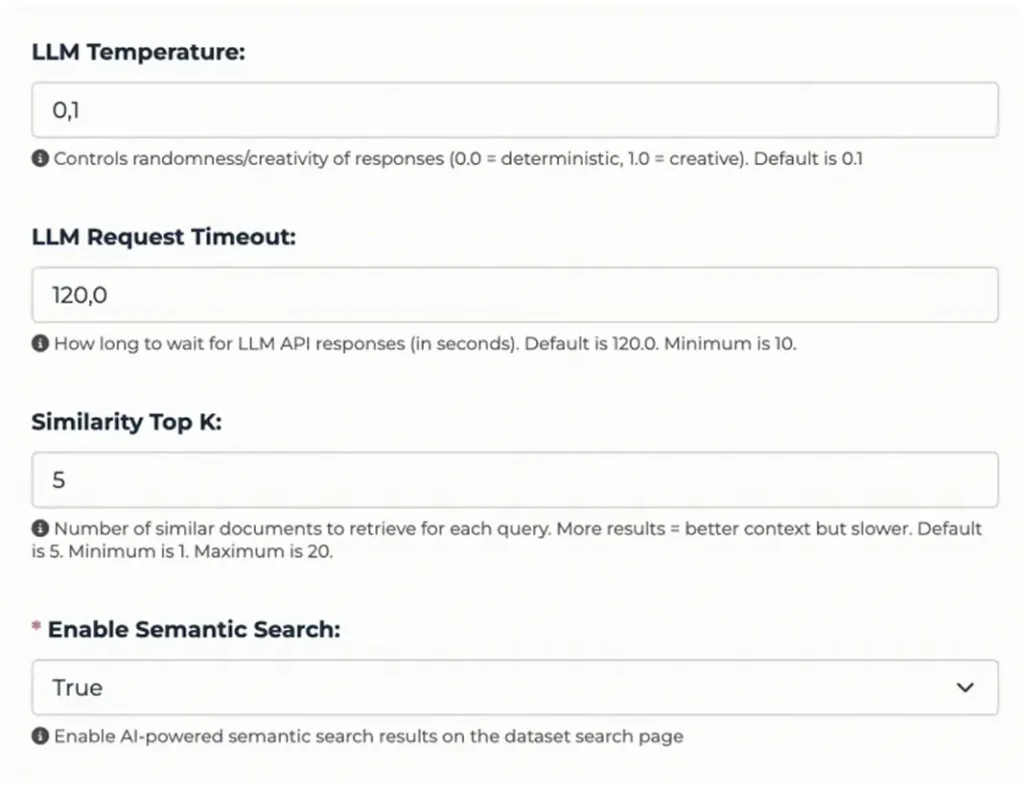
Configuration is handled via the CKAN configuration file, and several runtime parameters can be adjusted through the Admin Panel UI:
- Model temperature
- Request timeouts
- Semantic search top-k values
- Query expansion toggles
- DataStore result limits
- Context window settings (for Ollama)
This allows administrators to tune performance, cost, and response behaviour without redeploying the system.
Security and permission awareness
Security alignment with CKAN is fundamental. Ask AI respects CKAN’s native permission model. Private datasets remain inaccessible to unauthorised users. Permission labels are applied during filtering to ensure that search and AI responses only include datasets visible to the querying user.
If a user does not have access to a dataset, it is neither retrieved nor referenced in responses. When deployed with local AI models, data remains entirely within organisational infrastructure. For institutions with strict data residency requirements, this is a critical capability.
From Portal to Intelligent Interface
The transformation can be summarised simply:
Before:
- Keyword-only search
- Manual inspection of metadata
- SQL required for deeper analysis
After:
- Semantic similarity search
- Conversational dataset exploration
- LLM-generated DataStore queries
This shift repositions CKAN from a repository to an intelligent interface layer over public sector knowledge assets.
A practical step towards AI-enabled open data
Artificial intelligence is often discussed abstractly in the open data ecosystem. Ask AI takes a pragmatic approach. It does not attempt to reinvent CKAN or introduce excessive architectural overheads. It focuses on usability, discovery, and interaction.
For organisations managing large data portals, the question is no longer whether AI will influence user expectations. It already has. The question is whether your portal will remain a searchable archive, or evolve into a conversational, intelligent gateway to public data.
Ask AI represents one practical path forward.
Sign up for a demo
Sign up for a demo, and we can talk about your project and how Ask AI can improve your users’ interactions with data . Get in touch to discuss how we can help.



