
This article shows you the step-by-step for installing the most common CKAN extensions that people like to get running, DataStore and DataPusher.
CKAN Datastore
The CKAN DataStore extension is a database solution tailored for structured (tabular) data derived from CKAN resources. It facilitates the extraction of data from resource files and its subsequent storage within the DataStore. The DataStore database stores data in tabular format, making it suitable for structured datasets such as spreadsheets, CSV’s, JSON, XML and even Database tables.
Upon uploading of a data resource into the DataStore, users benefit from:
- Automated data previews: Accessible directly from the resource’s page, leveraging functionalities such as the DataTables view extension.
- Utilisation of the Data API: streamlined search, filtering, and updating of data without necessitating the complete download and upload of the data file.
- Seamless integration of the DataStore into the CKAN API and its accompanying authorization framework.
Typically employed in conjunction with the DataPusher, the DataStore extension seamlessly accommodates the automated uploading of data from compatible files, whether sourced from local files or external links.
The documentation for installing DataStore is located here: https://docs.ckan.org/en/latest/maintaining/datastore.html#setting-up-the-datastore.
DataStore Installation
In the instructions before we set a database user called datastore_default and then creates the datastore database called datastore_default using the ckan_default user to create the database:
sudo -u postgres createuser -S -D -R -P -l datastore_default
sudo -u postgres createdb -O ckan_default datastore_default -E utf-8
Now the CKAN configuration file (ckan.ini) should be updated to the password that was applied when creating the datastore_default user
ckan.datastore.write_url = \ postgresql://ckan_default:pass@localhost/datastore_default
ckan.datastore.read_url = \ postgresql://datastore_default:pass@localhost/datastore_default
It then applies permissions using the datastore cli command:
ckan -c /etc/ckan/default/ckan.ini datastore set-permissions | sudo -u postgres psql –set ON_ERROR_STOP=1
This should now be tested using an API command: datastore_search?resource_id=_table_metadata. If there are no errors when running this command then installation has been successfully completed.
curl -X GET \ “http://127.0.0.1:5000/api/3/action/datastore_search?resource_id=_table_metadata”
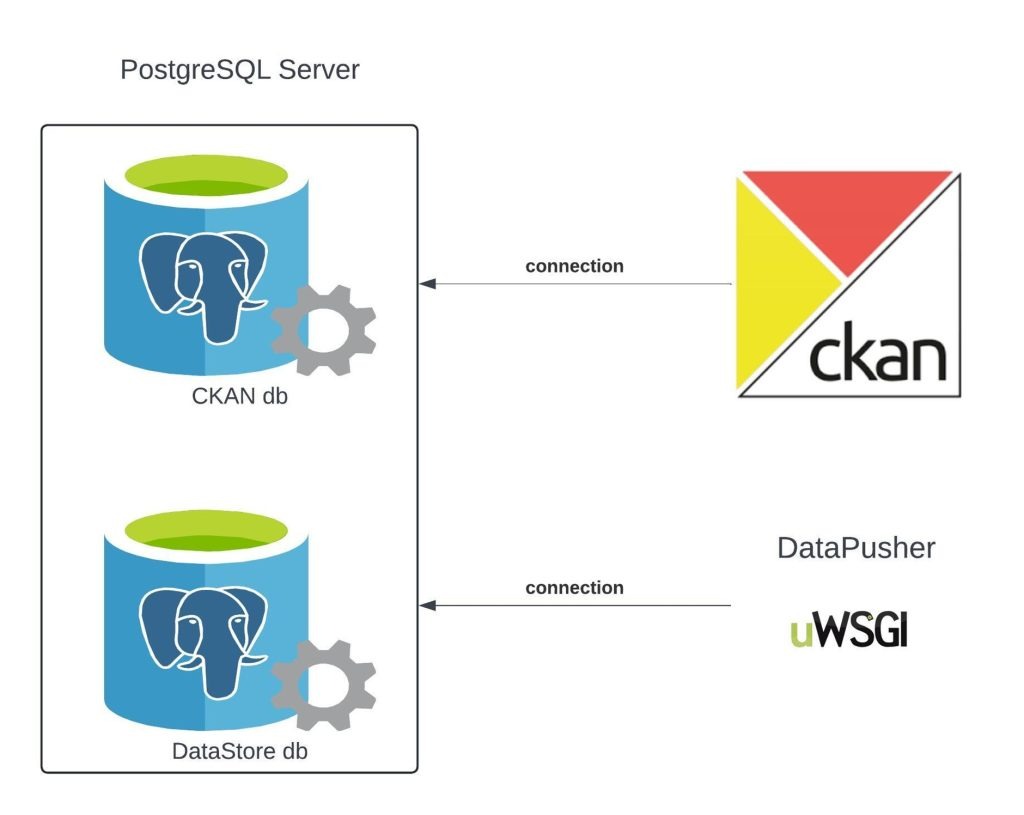
Simplified view of the database connections from the CKAN server and the DataPusher uWSGI server to the CKAN and DataStore databases
CKAN Datapusher
The DataPusher is another CKAN extension and is a crucial component in the CKAN ecosystem, designed to streamline the process of pushing data into the CKAN DataStore database.
The DataPusher serves as a bridge between external data sources and a CKAN instance, facilitating the seamless integration of datasets into the CKAN platform. Its primary function is to automate the process of uploading and updating datasets in CKAN, ensuring that the data available in CKAN remains current and accurate.
Key features of the CKAN DataPusher include:
- Automated data upload: The DataPusher automates the process of uploading datasets to CKAN, eliminating the need for manual intervention.
- Real-time data synchronisation: The DataPusher enables real-time synchronisation of data between external sources and CKAN, ensuring that changes made to datasets are promptly reflected in the CKAN instance.
- Data validation: The DataPusher validates the data before uploading it to CKAN, ensuring its integrity and consistency.
- Metadata extraction: The DataPusher extracts metadata from the datasets and maps it to CKAN’s metadata schema, making the datasets more discoverable and accessible within the CKAN platform.
- Support for various data formats: The DataPusher supports a wide range of data formats, including CSV, Excel, JSON, and others, making it versatile and adaptable to different data sources.
- Scalability: It is designed to handle large volumes of data efficiently, ensuring optimal performance even when dealing with extensive datasets.
Overall, the CKAN DataPusher simplifies the process of managing and updating datasets in CKAN, enabling organisations to make their data more accessible and actionable for users.
DataPusher Installation
Here are the instructions for installing a “development” DataPusher on an Ubuntu Server
We first install the system libraries. These libraries may have already been installed if you have CKAN up and running:
sudo apt-get install python-dev python-virtualenv build-essential \ libxslt1-dev libxml2-dev zlib1g-dev git libffi-dev
We then need to clone (download) the DataPusher software:
git clone https://github.com/ckan/datapusher
cd datapusher
Next, we need to install the library dependencies:
pip install -r requirements.txt
pip install -r requirements-dev.txt
And finally we install the actual DataPusher software:
pip install -e .
We can run DataPusher in “development mode” using the following command:
python datapusher/main.py deployment/datapusher_settings.py
And we can then access DataPusher with the following URL:
http://localhost:8800/
The DataPusher is also included as a separate Docker Compose service in the official CKAN Docker installation.
The Future of DataPusher
Recent efforts have been dedicated to two analogous projects, XLoader and DataPusher+. It is anticipated that in the foreseeable future, both XLoader and DataPusher+ will supersede DataPusher as the primary mechanisms for uploading and updating structured datasets within the CKAN ecosystem.
Related video: Install DataPusher and DataStore | CKAN 2.10 | Ubuntu
About Brett Jones
With a 30-year tenure in the tech industry, Brett Jones brings a wealth of experience across the globe. His career has traversed six international cities: Wellington, Sydney, Melbourne, New York, San Francisco, and Berlin, with an additional stop in Dhahran, Saudi Arabia. Throughout his journey, he has donned various hats at three tech giants – BEA Systems, Sun Microsystems, and Hewlett Packard. His expertise spans across diverse roles, including developer, solution architect/design, systems engineering, DevOps, and integration.
Highlights of Brett’s impressive career include working on the trading floor at 60 Wall Street during the dot-com boom, experiencing the heart of Silicon Valley, and dedicating the last five years to the New Payments Platform (NPP) project in Sydney. His recent focus areas have been build automation, bespoke tool creation, application performance monitoring, and data engineering and analysis.



